Нормальное распределение (Гаусса) в Excel. Нормальное распределение (Гаусса) в Excel Обратное нормальное распределение
В теории вероятностей рассматривается достаточно большое количество разнообразных законов распределения. Для решения задач, связанных с построением контрольных карт, представляют интерес лишь некоторые из них. Важнейшим из них является нормальный закон распределения , который применяется для построения контрольных карт, используемых при контроле по количественному признаку , т.е. когда мы имеем дело с непрерывной случайной величиной. Нормальный закон распределения занимает среди других законов распределения особое положение. Это объясняется тем, что, во-первых, наиболее часто встречается на практике, и, во-вторых, он является предельным законом, к которому приближаются другие законы распределения при весьма часто встречающихся типичных условиях. Что касается второго обстоятельства, то в теории вероятностей доказано, что сумма достаточно большого числа независимых (или слабо зависимых) случайных величин, подчиненных каким угодно законам распределения (при соблюдении некоторых весьма нежестких ограничений), приближенно подчиняется нормальному закону, и это выполняется тем точнее, чем большее количество случайных величин суммируется. Большинство встречающихся на практике случайных величин, таких, например, как ошибки измерений, могут быть представлены как сумма весьма большего числа сравнительно малых слагаемых - элементарных ошибок, каждая из которых вызвана действием отдельной причины, независящей от остальных. Нормальный закон проявляется в тех случаях, когда случайная переменная Х является результатом действия большого числа различных факторов. Каждый фактор в отдельности на величину Х влияет незначительно, и нельзя указать, какой именно влияет в большей степени, чем остальные.
Нормальное распределение (распределение Лапласа–Гаусса ) – распределение вероятностей непрерывной случайной величины Х такое, что плотность распределения вероятностей при - ¥ <х< + ¥ принимает действительное значение:
Ехр  (3)
(3)
То есть, нормальное распределение характеризуется двумя параметрами m и s, где m - математическое ожидание; s- стандартное отклонение нормального распределения.
Величина s 2 – это дисперсия нормального распределения.
Математическое ожидание m характеризует положение центра распределения, а стандартное отклонение s (СКО) является характеристикой рассеивания (рис. 3).
f(x) f(x)
 |
Рисунок 3 – Функции плотности нормального распределения с:
а) разными математическими ожиданиями m; б) разными СКО s .
Таким образом, значением μ определяется положением кривой распределения на оси абсцисс. Размерность μ - та же, что и размерность случайной величины X . С ростом математического ожидания mобе функции сдвигается параллельно вправо. С убывающей дисперсией s 2 плотность все больше концентрируется вокруг m, в то время как функция распределения становится все более крутой.
Значением σ определяется форма кривой распределения. Поскольку площадь под кривой распределения должна всегда оставаться равной единице, то при увеличении σ кривая распределения становится более плоской. На рис. 3.1 показаны три кривые при разных σ: σ1 = 0,5; σ2 = 1,0; σ3 = 2,0.

Рисунок 3.1 – Функции плотности нормального распределения с разными СКО s .
Функция распределения (интегральная функция) имеет вид (рис. 4):

 (4)
(4)
Рисунок 4 – Интегральная (а) и дифференциальная (б) функции нормального распределения
Особенно важно то линейное преобразование нормально распределенной случайной переменной Х , после которого получается случайная переменная Z с математическим ожиданием 0 и дисперсией 1. Такое преобразование называется нормированием:
Его можно провести для каждой случайной переменной. Нормирование позволяет все возможные варианты нормального распределения свести к одному случаю: m = 0, s = 1.
Нормальное распределение с m = 0, s = 1 называется нормированным нормальным распределением (стандартизованным) .
Стандартное нормальное распределение (стандартное распределение Лапласа–Гаусса или нормированное нормальное распределение) – это распределение вероятностей стандартизованной нормальной случайной величины Z , плотность распределения которой равна:
при - ¥ <z < + ¥
Значения функции Ф(z) определяется по формуле:
 (7)
(7)
Значения функции Ф(z) и плотности ф(z) нормированного нормального распределения рассчитаны и сведены в таблицы (табулированы). Таблица составлена только для положительных значений z поэтому:
Ф (–z) = 1 –Ф (z) (8)
С помощью этих таблиц можно определить не только значения функции и плотности нормированного нормального распределения для заданного z , но и значения функции общего нормального распределения, так как:
![]() ; (9)
; (9)
![]() . 10)
. 10)
Во многих задачах, связанных с нормально распределенными случайными величинами, приходится определять вероятность попадания случайной величины Х , подчиненной нормальному закону с параметрами m и s, на определенный участок. Таким участком может быть, например, поле допуска на параметр от верхнего значения U до нижнего L .
Вероятность попадания в интервал от х 1 до х 2 можно определить по формуле:
Таким образом, вероятность попадания случайной величины (значение параметра) Х в поле допуска определяется формулой
Можно найти вероятность того, что случайная переменная Х окажется в пределах μ k s. Полученные значения для k =1,2 и 3 следующие (также смотрим рис. 5):
Таким образом, если какое-либо значение появляется за пределами трехсигмового участка, в котором находятся 99,73% всех возможных значений, а вероятность появления такого события очень мала (1:270), следует считать, что рассматриваемое значение оказалось слишком маленьким или слишком большим не из-за случайного варьирования, а из-за существенной помехи в самом процессе, способной вызывать изменения в характере распределения.
Участок, лежащий внутри трехсигмовых границ, называют также областью статистического допуска соответствующей машины или процесса.
Закон нормального распределения, так называемый закон Гаусса - один из самых распространенных законов. Это фундаментальный закон в теории вероятностей и в ее применении. Нормальное распределение чаще всего встречается в изучении природных и социально-экономических явлений. Иначе говоря, большинство статистических совокупностей в природе и обществе подчиняется закону нормального распределения. Соответственно можно сказать, что совокупности большого числа крупных по объему выборок подчиняются закону нормального распределения. Те из совокупностей, которые отклоняются от нормального распределения в результате специальных преобразований, могут быть приближены к нормальному. В связи с этим следует помнить, что принципиальная особенность этого закона применительно к другим законам распределения заключается в том, что он является законом границы, к которой приближаются другие законы распределения в определенных (типовых) условиях.
Следует отметить, что термин "нормальное распределение" имеет условный смысл, как общепринятый в математической и статистико-математической литературе термин. Утверждение, что тот или иной признак любого явления подчиняется закону нормального распределения, вовсе не означает незыблемость норм, будто присущих исследуемому явлению, а отнесения последнего ко второму виду закона не означает какую-то анормальнисть данного явления. В этом смысле термин "нормальное распределение" не совсем удачен.
Нормальное распределение (закон Гаусса-Лапласа) является типом непрерывного распределения. Где Муавр (одна тысяча семьсот семьдесят три, Франция) вывел нормальный закон распределения вероятностей. Основные идеи этого открытия были использованы в теории ошибок впервые К. Гауссом (1809, Германия) и А.Лапласом (1812, Франция), которые внесли витчутний теоретический вклад в разработку самого закона. В частности, К. Гаусс в своих разработках исходил из признания наиболее вероятным значением случайной величины-среднюю арифметическую. Общие условия возникновения нормального распределения установил А.М.Ляпунова. Им было доказано, что если исследуемая признак представляет собой результат суммарного воздействия многих факторов, каждый из которых мало связан с большинством остальных, и влияние каждого фактора на конечный результат гораздо перекрывается суммарным воздействием всех остальных факторов, то распределение становится близким к нормальному.
Нормальным называют распределение вероятностей непрерывной случайной величины, имеет плотность:
1 +1 (& #) 2
/ (х, х, <т) = - ^ е 2 ст2
где х - математическое ожидание или средняя величина. Как видно, нормальное распределение определяется двумя параметрами: х и °. Чтобы задать нормальное распределение, достаточно знать математическое ожидание или среднее и среднее квадратическое отклонение. Эти две величины определяют центр группировки и форму
кривой на графике. График функции и (хх, в) называется нормальной кривой (кривая Гаусса) с параметрами х и в (рис. 12).
Кривая нормального распределения имеет точки перегиба при X ± 1. Если представить графически, то между X = + l и 1 = -1 находится 0,683 части всей площади кривой (т.е. 68,3%). В границах X = + 2 и X- 2. находятся 0,954 площади (95,4%), а между X = + 3 и X = - 3 - 0,997 части всей площади распределения (99,7%). На рис. 13 проиллюстрирован характер нормального распределения с одно-, двух- и трисигмовою границами.
При нормальном распределении средняя арифметическая, мода и медиана будут равны между собой. Форма нормальной кривой имеет вид одновершинные симметричной кривой, ветки которой асимптотически приближаются к оси абсцисс. Наибольшая ордината кривой соответствует х = 0. В этой точке на оси абсцисс размещается численное значение признаков, равное средней арифметической, моде и медиане. По обе стороны от вершины кривой ее ветки приходят, изменяя в определенных точках форму выпуклости на вогнутость. Эти точки симметричные и соответствуют значениям х = ± 1, то есть величинам признаки, отклонения которых от средней численно равна среднему квадратичному отклонению. Ордината, что соответствует средней арифметической, делит всю площадь между кривой и осью абсцисс пополам. Итак, вероятности появления значений исследуемого признака больших и меньших средней
арифметической будут равны 0,50, то есть х, (~ ^ х) = 0,50 В
Рис.12. Кривая нормального распределения (кривая Гаусса)
Форму и положение нормальной кривой обусловливают значение средней и среднего квадратичного отклонения. Математически доказано, что изменение величины среднего (математического ожидания) не изменяет формы нормальной кривой, а приводит лишь к ее смещение вдоль оси абсцисс. Кривая сдвигается вправо, если ~ растет, и влево, если ~ приходит.

Рис.14. Кривые нормального распределения с различными значениями параметра в
Об изменении формы графика нормальной кривой при изменении
среднего квадратичного отклонения можно судить по максимуму
дифференциальной функции нормального распределения, равный 1
Как видно, при росте величины ° максимальная ордината кривой будет уменьшаться. Следовательно, кривая нормального распределения будет сжиматься к оси абсцисс и принимать более плосковершинных форму.
И, наоборот, при уменьшении параметра в нормальная кривая вытягивается в положительном направлении оси ординат, а форма "колокола" становится более гостровершиною (рис. 14). Отметим, что независимо от величины параметров ~ и в площадь, ограниченная осью абсцисс и кривой, всегда равен единице (свойство плотности распределения). Это наглядно иллюстрирует график (рис. 13).
Названные выше особенности проявления "нормальности" распределения позволяют выделить ряд общих свойств, которые имеют кривые нормального распределения:
1) любой нормальный кривая достигает точки максимума (х = х) приходит непрерывно вправо и влево от него, постепенно приближаясь к оси абсцисс;
2) любой нормальный кривая симметрична по отношению к прямой,
параллельной оси ординат и проходит через точку максимума (х = х)
максимальная ордината равна ^^^ я;
3) любой нормальный кривая имеет форму "колокола", имеет выпуклость, которая направлена вверх к точке максимума. В точках х ~ ° и х + в она меняет выпуклость, и, чем меньше а, тем острее "колокол", а чем больше а, тем более похилишою становится вершина "колокола" (рис.14). Изменение математического ожидания (при неизменной величине
в) не приводит к модификации формы кривой.
При х = 0 и ° = 1 нормальную кривую называют нормированной кривой или нормальным распределением в каноническом виде.
Нормированная кривая описывается следующей формуле:
Построение нормальной кривой по эмпирическим данным производится по формуле:
пи 1 - "" = --- 7 = е
где и ™ - теоретическая частота каждого интервала (группы) распределения; "- Сумма частот, равную объему совокупности; "- шаг интервала;
же - отношение длины окружности к ее диаметру, которое составляет
е - основание натуральных логарифмов, равна 2,71828;
Вторая и третья части формулы) является функцией
нормированного отклонения ЦЧ), которую можно рассчитать для любых значений X. Таблицы значений ЦЧ) обычно называют "таблицы ординат нормальной кривой" (приложение 3). При использовании этих функций рабочая формула нормального распределения приобретает простого вида:
Пример. Рассмотрим случай построения нормальной кривой на примере данных о распределении 57 работников по уровню дневного заработка (табл. 42). По данным таблицы 42, находим среднюю арифметическую:
~ = ^ = И6 54 =
Рассчитываем среднее квадратическое отклонение:
Для каждой строки таблицы находим значение нормированного отклонения
х и ~ х | 12 г => - = - ^ 2 = 1.92
а 6.25 (дд Я первого интервала и т.д.).
В графе 8 табл. 42 записываем табличное значение функции Ди) из приложения, например, для первого интервала X = 1.92 находим "1,9" против "2" (0.0632).
Для вычисления теоретических частот, то есть ординат кривой нормального распределения, вычисляется множитель:
* = ^ = 36,5 а 6,25
Все найденные табличные значения функции / (г) умножаем на 36,5. Так, для первого интервала получаем 0,0632x36,5 = 2,31 т. Принято немногочисленные
частоты (п "<5) объединять (в нашем примере - первые два и последние два интервала).
Если крайние теоретические частоты значительно отличаются от нуля, расхождение между суммами эмпирических и теоретических частот может оказаться значительной.
График распределения эмпирических и теоретических частот (нормальная кривая) по данным рассматриваемого примера показано на рисунке 15.
Рассмотрим пример определения частот нормального распределения для случая, когда в крайних интервалах отсутствует частота (табл. 43). Здесь эмпирическая
X - нормированное отклонение, (в) а - среднее квадратическое отклонение.
частота первого интервала равна нулю. Полученная сумма неуточненных частот не равна сумме их эмпирических значений (56 * 57). В этом случае рассчитывается теоретическая частота для умывания полученных значений центра интервала, нормированного отклонения и его функции.
В таблице 43 эти величины обведено прямоугольником. При построении графика нормальной кривой в таких случаях теоретическую кривую продолжают. В рассматриваемом случае нормальная кривая будет продолжена в сторону отрицательных отклонений от средней, поскольку первая не уточнена частота равна 5. Рассчитана теоретическая частота (уточненная) для первого интервала будет равен единице. По сумме уточнены частоты совпадают с эмпирическими
Таблица 42
|
Расчетные величины |
Статистические параметры |
||||||||||||||
|
Интервал, |
Количество единиц, |
х) 2 n¡ |
нормированное отделения, |
теоретическая частота нормального ряда распределения, / 0) х - а |
|||||||||||
|
>> |
|||||||||||||||
|
Тысяча шестьсот пятьдесят четыре |
|||||||||||||||
|
а = 6,25 |
^ i = 36,5 а |
||||||||||||||
Таблица 43
Расчет частот нормального распределения (выравнивание эмпирических частот по нормальному закону)
|
Количество единиц, |
Расчетные величины |
Статистические параметры |
||||||||||||
|
Интервал (и-2) |
Срединное значение (центр) интервала, |
(je, -xf |
^ x t -x) 1 n и |
нормированное отклонение x s - х t = x --L |
табличное значение функции, f (t) |
теоретическая частота нормального ряда распределения |
уточненное значение теоретической частоты, |
|||||||
|
ш |
- |
- |
- |
- |
- |
|||||||||
|
о = 2,41 |
||||||||||||||

Рис. 15. Эмпирический распределение (1) и нормальная кривая (2)
Кривую нормального распределения по исследуемой совокупности можно построить и другим способом (в отличие, от рассмотренного выше). Так, если необходимо иметь приближенную представление о соответствии фактического распределения нормальному, вычисления осуществляют следующим последовательности. Определяют максимальную ординату, которая соответствует среднему размеру признаки), затем, вычислив среднее квадратическое отклонение, рассчитывают координаты точек кривой нормального распределения по схеме, изложенной в таблицах 42 и 43. Так, по исходным и расчетным данным таблицы 43 должны среднюю ~ = 26 Эта величина средней совпадает с центром четвертого интервала (25-27). Итак, частота этого интервала "20" может быть принята (при построении графика) максимальной ординату). Имея исчисленную дисперсию (в = 2,41 см. Табл. 43), рассчитываем значения координат всех необходимых точек кривой нормального распределения (табл. 44, 45). По полученным координатам чертим нормальную кривую (рис. 16), приняв максимальной ординату частоту четвертого интервала.
Согласованность эмпирического распределения с нормальным может быть установлена также путем упрощенных расчетов. Так, если отношение показателя степени асимметрии (^) к своей середнеквадраты-ческой ошибки ш а "или отношение показателя эксцесса (Е х) к своей среднеквадратического ошибки т & превышает по абсолютной величине число« 3 », делается вывод о несоответствии эмпирического распределения характера нормального распределения (то есть,
А ц Е х
если ™ А> 3 или ш е "> 3).
Есть и другие, нетрудоемкие приемы установления "нормальности" распределения: а) сравнение средней арифметической с модой и медианой; б) использование цифр Вестергард; в) применение графического образа с помощью полулогарифмическая сетки Турбина; г) вычисление специальных критериев согласования и др.
Таблица 44
Координаты 7 точек кривой нормального распределения
Таблица 45
Вычисление координат точек кривой нормального распределения
|
x - 1,5 (7 = |
х - а = 23,6 |
х - 0,5 (7 = = 24,8 |
х + 0,5ст = 27,2 |
х + а = 28,4 |
X + 1,5 (7 = |
||

Рис.16. Кривая нормального распределения, построенная по семи точках
На практике при исследовании совокупности на предмет согласования ее распределения с нормальным часто пользуются "правилом 3сг".
Математически доказано вероятность того, что отклонение от средней по абсолютной величине будет меньше тройного среднего квадратичного отклонения, равно 0,9973, то есть, вероятность того, что абсолютная величина отклонения превышает тройное среднее квадратическое отклонение, равна 0,0027 или очень мала. Исходя из принципа невозможности маловероятных событий, можно считать практически невозможным "случай превышения" 3 ст. Если случайная величина распределена нормально, то абсолютная величина ее отклонения от математического ожидания (средней) не превышает тройного среднего квадратичного отклонения.
В практических расчетах действуют таким образом. Если при неизвестном характере распределения исследуемой случайной величины рассчитанное значение отклонения от средней окажется меньше значения 3 СТ, то есть основания полагать, что исследуемая признак распределена нормально. Если же указанный параметр превысит числовое значение 3 СТ, можно считать, что распределение исследуемой величины не согласуется с нормальным распределением.
Вычисления теоретических частот для исследуемого эмпирического ряда распределения принято называть выравниванием эмпирических кривых по нормальному (или любом другом) закона распределения. Этот процесс имеет важное как теоретическое, так практическое значение. Выравнивание эмпирических данных раскрывает закономерность в их распределении, которая может быть завуалирована случайной формой своего проявления. Установленную таким образом закономерность можно использовать для решения ряда практических задач.
С распределением, близким к нормальному, исследователь встречается в различных сферах науки и областях практической деятельности человека. В экономике такого рода распределения встречаются реже, чем, скажем, в технике или биологии. Обусловлено это самой природой социально-экономических явлений, которые характеризуются большой сложностью взаимосвязанных и взаимосвязанных факторов, а также наличием ряда условий, ограничивающих свободную "игру" случаев. Но экономист должен обращаться к нормальному распределению, анализируя строение эмпирических распределений, как к некоторому эталону. Такое сравнение позволяет выяснить характер тех внутренних условий, которые определяют данную фигуру распределения.
Проникновение сферы статистических исследований в область социально-экономических явлений позволило раскрыть существование большого количества различного типа кривых распределения. Однако не надо считать, что теоретическая концепция кривой нормального распределения вообще мало пригодна в статистико-математическом анализе такого типа явлений. Она может быть не всегда приемлема в анализе конкретного статистического распределения, но в области теории и практики выборочного метода исследования имеет первостепенное значение.
Назовем основные аспекты применения нормального распределения в статистико-математическом анализе.
1. Для определения вероятности конкретного значения признака. Это необходимо при проверке гипотез о соответствии того или иного эмпирического распределения нормальному.
2. При оценке ряда параметров, например, средних, методом максимального правдоподобия. Суть его заключается в определении такого закона, которому подчиняется совокупность. Определяется и оценка, которая дает максимальные значения. Лучшее приближение к параметрам генеральной совокупности дает отношение:
у = - 2 = е 2
3. Для определения вероятности выборочных средних относительно генеральных средних.
4. При определении доверительного интервала, в котором находится приближенное значение характеристик генеральной совокупности.
Во многих задачах, связанных с нормально распределенными случайными величинами, приходится определять вероятность попадания случайной величины , подчиненной нормальному закону с параметрами , на участок от до . Для вычисления этой вероятности воспользуемся общей формулой
где - функция распределения величины .
Найдем функцию распределения случайной величины , распределенной по нормальному закону с параметрами . Плотность распределения величины равна:
Отсюда находим функцию распределения
 . (6.3.3)
. (6.3.3)
Сделаем в интеграле (6.3.3) замену переменной
и приведем его к виду:
 (6.3.4)
(6.3.4)
Интеграл (6.3.4) не выражается через элементарные функции, но его можно вычислить через специальную функцию, выражающую определенный интеграл от выражения или (так называемый интеграл вероятностей), для которого составлены таблицы. Существует много разновидностей таких функций, например:
 ;
;

и т.д. Какой из этих функций пользоваться – вопрос вкуса. Мы выберем в качестве такой функции
 . (6.3.5)
. (6.3.5)
Нетрудно видеть, что эта функция представляет собой не что иное, как функцию распределения для нормально распределенной случайной величины с параметрами .
Условимся называть функцию нормальной функцией распределения. В приложении (табл. 1) приведены таблицы значений функции .
Выразим функцию распределения (6.3.3) величины с параметрами и через нормальную функцию распределения . Очевидно,
Теперь найдем вероятность попадания случайной величины на участок от до . Согласно формуле (6.3.1)
Таким образом, мы выразили вероятность попадания на участок случайной величины , распределенной по нормальному закону с любыми параметрами, через стандартную функцию распределения , соответствующую простейшему нормальному закону с параметрами 0,1. Заметим, что аргументы функции в формуле (6.3.7) имеют очень простой смысл: есть расстояние от правого конца участка до центра рассеивания, выраженное в средних квадратических отклонениях; - такое же расстояние для левого конца участка, причем это расстояние считается положительным, если конец расположен справа от центра рассеивания, и отрицательным, если слева.
Как и всякая функция распределения, функция обладает свойствами:
3. - неубывающая функция.
Кроме того, из симметричности нормального распределения с параметрами относительно начала координат следует, что
Пользуясь этим свойством, собственно говоря, можно было бы ограничить таблицы функции только положительными значениями аргумента, но, чтобы избежать лишней операции (вычитание из единицы), в таблице 1 приложения приводятся значения как для положительных, так и для отрицательных аргументов.

На практике часто встречается задача вычисления вероятности попадания нормально распределенной случайной величины на участок, симметричный относительно центра рассеивания . Рассмотрим такой участок длины (рис. 6.3.1). Вычислим вероятность попадания на этот участок по формуле (6.3.7):
Учитывая свойство (6.3.8) функции и придавая левой части формулы (6.3.9) более компактный вид, получим формулу для вероятности попадания случайной величины, распределенной по нормальному закону на участок, симметричный относительно центра рассеивания:
![]() .
(6.3.10)
.
(6.3.10)
Решим следующую задачу. Отложим от центра рассеивания последовательные отрезки длиной (рис. 6.3.2) и вычислим вероятность попадания случайной величины в каждый из них. Так как кривая нормального закона симметрична, достаточно отложить такие отрезки только в одну сторону.

По формуле (6.3.7) находим:
 (6.3.11)
(6.3.11)
Как видно из этих данных, вероятности попадания на каждый из следующих отрезков (пятый, шестой и т.д.) с точностью до 0,001 равны нулю.
Округляя вероятности попадания в отрезки до 0,01 (до 1%), получим три числа, которые легко запомнить:
0,34; 0,14; 0,02.
Сумма этих трех значений равна 0,5. Это значит, что для нормально распределенной случайной величины все рассеивания (с точностью до долей процента) укладывается на участке .
Это позволяет, зная среднее квадратическое отклонение и математическое ожидание случайной величины, ориентировочно указать интервал её практически возможных значений. Такой способ оценки диапазона возможных значений случайной величины известен в математической статистике под названием «правило трех сигма». Из правила трех сигма вытекает также ориентировочный способ определения среднего квадратического отклонения случайной величины: берут максимальное практически возможное отклонение от среднего и делят его на три. Разумеется, этот грубый прием может быть рекомендован, только если нет других, более точных способов определения .
Пример 1. Случайная величина , распределенная по нормальному закону, представляет собой ошибку измерения некоторого расстояния. При измерении допускается систематическая ошибка в сторону завышения на 1,2 (м); среднее квадратическое отклонения ошибки измерения равно 0,8 (м). Найти вероятность того, что отклонение измеренного значения от истинного не превзойдет по абсолютной величине 1,6 (м).
Решение. Ошибка измерения есть случайная величина , подчиненная нормальному закону с параметрами и . Нужно найти вероятность попадания этой величины на участок от до . По формуле (6.3.7) имеем:
Пользуясь таблицами функции (приложение, табл. 1), найдем:
![]() ;
,
;
,
Пример 2. Найти ту же вероятность, что и в предыдущем примере, но при условии, что систематической ошибки нет.
Решение. По формуле (6.3.10), полагая , найдем:
Пример 3. По цели, имеющей вид полосы (автострада), ширина которой равна 20 м, ведется стрельба в направлении, перпендикулярном автостраде. Прицеливание ведется по средней линии автострады. Среднее квадратическое отклонение в направлении стрельбы равно м. Имеется систематическая ошибка в направлении стрельбы: недолет 3 м. Найти вероятность попадания в автостраду при одном выстреле.
Нормальное распределение (normal distribution ) - играет важную роль в анализе данных.
Иногда вместо термина нормальное распределение употребляют термин гауссовское распределение в честь К. Гаусса (более старые термины, практически не употребляемые в настоящее время: закон Гаусса, Гаусса-Лапласа распределение).
Одномерное нормальное распределение
Нормальное распределение имеет плотность::
В этой формуле , фиксированные параметры, - среднее , - стандартное отклонение .
Графики плотности при различных параметрах приведены .
Характеристическая функция нормального распределения имеет вид:
![]()
Дифференцируя характеристическую функцию и полагая t = 0 , получаем моменты любого порядка.
Кривая плотности нормального распределения симметрична относительно и имеет в этой точке единственный максимум, равный
Параметр стандартного отклонения меняется в пределах от 0 до ∞.
Среднее меняется в пределах от -∞ до +∞.
При увеличении параметра кривая растекается вдоль оси х , при стремлении к 0 сжимается вокруг среднего значения (параметр характеризует разброс, рассеяние).
При изменении кривая сдвигается вдоль оси х (см. графики).
Варьируя параметры и , мы получаем разнообразные модели случайных величин, возникающие в телефонии.
Типичное применение нормального закона в анализе, например, телекоммуникационных данных - моделирование сигналов, описание шумов, помех, ошибок, трафика.
Графики одномерного нормального распределения

Рисунок 1. График плотности нормального распределения: среднее равно 0, стандартное отклонение 1

Рисунок 2. График плотности стандартного нормального распределения с областями, содержащими 68% и 95% всех наблюдений

Рисунок 3. Графики плотностей нормальных распределений c нулевым средним и разными отклонениями (=0.5, =1, =2)

Рисунок 4 Графики двух нормальных распределений N(-2,2) и N(3,2).
Заметьте, центр распределения сдвинулся при изменении параметра .
Замечание
В программе STATISTICA под обозначением N(3,2) понимается нормальный или гауссов закон с параметрами: среднее = 3 и стандартное отклонение =2.
В литературе иногда второй параметр трактуется как дисперсия , т.е. квадрат стандартного отклонения.
Вычисления процентных точек нормального распределения с помощью вероятностного калькулятора STATISTICA
С помощью вероятностного калькулятора STATISTICA можно вычислить различные характеристики распределений, не прибегая к громоздким таблицам, используемым в старых книгах.
Шаг 1. Запускаем Анализ / Вероятностный калькулятор / Распределения .
В разделе распределения выберем нормальное .

Рисунок 5. Запуск калькулятора вероятностных распределений
Шаг 2. Указываем интересующие нас параметры.
Например, мы хотим вычислить 95% квантиль нормального распределения со средним 0 и стандартным отклонением 1.
Укажем эти параметры в полях калькулятора (см. поля калькулятора среднее и стандартное отклонение).
Введем параметр p=0,95.
Галочка «Обратная ф.р». отобразится автоматически. Поставим галочку «График».
Нажмем кнопку «Вычислить» в правом верхнем углу.

Рисунок 6. Настройка параметров
Шаг 3. В поле Z получаем результат: значение квантиля равно 1,64 (см. следующее окно).

Рисунок 7. Просмотр результата работы калькулятора

Рисунок 8. Графики плотности и функции распределения. Прямая x=1,644485




Рисунок 9. Графики функции нормального распределения. Вертикальные пунктирные прямые- x=-1.5, x=-1, x=-0.5, x=0


Рисунок 10. Графики функции нормального распределения. Вертикальные пунктирные прямые- x=0.5, x=1, x=1.5, x=2
Оценка параметров нормального распределения
Значения нормального распределения можно вычислить с помощью интерактивного калькулятора .
Двумерное нормальное распределение
Одномерное нормальное распределение естественно обобщается на двумерное нормальное распределение.
Например, если вы рассматриваете сигнал только в одной точке, то вам достаточно одномерного распределения, в двух точках - двумерного, в трех точках - трехмерного и т.д.
Общая формула для двумерного нормального распределения имеет вид:

Где - парная корреляция между X 1 и X 2 ;
X 1 соответственно;
Среднее и стандартное отклонение переменной X 2 соответственно.
Если случайные величины Х 1 и Х 2 независимы, то корреляция равна 0, = 0, соответственно средний член в экспоненте зануляется, и мы имеем:
f(x 1 ,x 2) = f(x 1)*f(x 2)
Для независимых величин двумерная плотность распадается в произведение двух одномерных плотностей.
Графики плотности двумерного нормального распределения

Рисунок 11. График плотности двумерного нормального распределения (нулевой вектор средних, единичная ковариационная матрица)

Рисунок 12. Сечение графика плотности двумерного нормального распределения плоскостью z=0.05

Рисунок 13. График плотности двумерного нормального распределения (нулевой вектор мат. ожидания, ковариационная матрица с 1 на главной диагонали и 0.5 на побочной)

Рисунок 14. Сечение графика плотности двумерного нормального распределения (нулевой вектор мат. ожидания, ковариационная матрица с 1 на главной диагонали и 0.5 на побочной) плоскостью z= 0.05

Рисунок 15. График плотности двумерного нормального распределения (нулевой вектор мат. ожидания, ковариационная матрица с 1 на главной диагонали и -0.5 на побочной)

Рисунок 16. Сечение графика плотности двумерного нормального распределения (нулевой вектор мат. ожидания, ковариационная матрица с 1 на главной диагонали и -0.5 на побочной) плоскостью z=0.05

Рисунок 17. Сечения графиков плотностей двумерного нормального распределения плоскостью z=0.05
Для лучшего понимания двумерного нормального распределения попробуйте решить следующую задачу.
Задача. Посмотрите на график двумерного нормального распределения. Подумайте, можно ли его представить, как вращение графика одномерного нормального распределения? Когда нужно применить прием деформации?
Будут и задачи для самостоятельного решения, к которым можно посмотреть ответы.
Нормальное распределение: теоретические основы
Примерами случайных величин, распределённых по нормальному закону, являются рост человека, масса вылавливаемой рыбы одного вида . Нормальность распределения означает следующее : существуют значения роста человека, массы рыбы одного вида, которые на интуитивном уровне воспринимаются как "нормальные" (а по сути - усреднённые), и они-то в достаточно большой выборке встречаются гораздо чаще, чем отличающиеся в бОльшую или меньшую сторону.
Нормальное распределение вероятностей непрерывной случайной величины (иногда - распределение Гаусса) можно назвать колоколообразным из-за того, что симметричная относительно среднего функция плотности этого распределения очень похожа на разрез колокола (красная кривая на рисунке выше).
Вероятность встретить в выборке те или иные значение равна площади фигуры под кривой и в случае нормального распределения мы видим, что под верхом "колокола", которому соответствуют значения, стремящиеся к среднему, площадь, а значит, вероятность, больше, чем под краями. Таким образом, получаем то же, что уже сказано: вероятность встретить человека "нормального" роста, поймать рыбу "нормальной" массы выше, чем для значений, отличающихся в бОльшую или меньшую сторону. В очень многих случаях практики ошибки измерения распределяются по закону, близкому к нормальному.
Остановимся ещё раз на рисунке в начале урока, на котором представлена функция плотности нормального распределения. График этой функции получен при рассчёте некоторой выборки данных в пакете программных средств STATISTICA . На ней столбцы гистограммы представляют собой интервалы значений выборки, распределение которых близко (или, как принято говорить в статистике, незначимо отличаются от) к собственно графику функции плотности нормального распределения, который представляет собой кривую красного цвета. На графике видно, что эта кривая действительно колоколообразная.
Нормальное распределение во многом ценно благодаря тому, что зная только математическое ожидание непрерывной случайной величины и стандартное отклонение, можно вычислить любую вероятность, связанную с этой величиной.
Нормальное распределение имеет ещё и то преимущество, что один из наиболее простых в использовании статистических критериев, используемых для проверки статистических гипотез - критерий Стьюдента - может быть использован только в том случае, когда данные выборки подчиняются нормальному закону распределения.
Функцию плотности нормального распределения непрерывной случайной величины можно найти по формуле:
 ,
,
где x - значение изменяющейся величины, - среднее значение, - стандартное отклонение, e =2,71828... - основание натурального логарифма, =3,1416...
Свойства функции плотности нормального распределения
Изменения среднего значения перемещают кривую функции плотности нормального распределения в направлении оси Ox . Если возрастает, кривая перемещается вправо, если уменьшается, то влево.
Если меняется стандартное отклонение, то меняется высота вершины кривой. При увеличении стандартного отклонения вершина кривой находится выше, при уменьшении - ниже.
Вероятность попадания значения нормально распределённой случайной величины в заданный интервал
Уже в этом параграфе начнём решать практические задачи, смысл которых обозначен в заголовке. Разберём, какие возможности для решения задач предоставляет теория. Отправное понятие для вычисления вероятности попадания нормально распределённой случайной величины в заданный интервал - интегральная функция нормального распределения.
Интегральная функция нормального распределения :
 .
.
Однако проблематично получить таблицы для каждой возможной комбинации среднего и стандартного отклонения. Поэтому одним из простых способов вычисления вероятности попадания нормально распределённой случайной величины в заданный интервал является использование таблиц вероятностей для стандартизированного нормального распределения.
Стандартизованным или нормированным называется нормальное распределение , среднее значение которого , а стандартное отклонение .
Функция плотности стандартизованного нормального распределения :
![]() .
.
Интегральная функция стандартизованного нормального распределения :
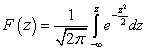 .
.
На рисунке ниже представлена интегральная функция стандартизованного нормального распределения, график которой получен при рассчёте некоторой выборки данных в пакете программных средств STATISTICA . Собственно график представляет собой кривую красного цвета, а значения выборки приближаются к нему.

Для увеличения рисунка можно щёлкнуть по нему левой кнопкой мыши.
Стандартизация случайной величины означает переход от первоначальных единиц, используемых в задании, к стандартизованным единицам. Стандартизация выполняется по формуле
На практике все возможные значения случайной величины часто не известны, поэтому значения среднего и стандартного отклонения точно определить нельзя. Их заменяют средним арифметическим наблюдений и стандартным отклонением s . Величина z выражает отклонения значений случайной величины от среднего арифметического при измерении стандартных отклонений.
Открытый интервал
Таблица вероятностей для стандартизированного нормального распределения, которая есть практически в любой книге по статистике, содержит вероятности того, что имеющая стандартное нормальное распределение случайная величина Z примет значение меньше некоторого числа z . То есть попадёт в открытый интервал от минус бесконечности до z . Например, вероятность того, что величина Z меньше 1,5, равна 0,93319.
Пример 1. Предприятие производит детали, срок службы которых нормально распределён со средним значением 1000 и стандартным отклонением 200 часов.
Для случайно отобранной детали вычислить вероятность того, что её срок службы будет не менее 900 часов.
Решение. Введём первое обозначение:
Искомая вероятность.
Значения случайной величины находятся в открытом интервале. Но мы умеем вычислять вероятность того, что случайная величина примет значение, меньшее заданного, а по условию задачи требуется найти равное или большее заданного. Это другая часть пространства под кривой плотности нормального распределения (колокола). Поэтому, чтобы найти искомую вероятность, нужно из единицы вычесть упомянутую вероятность того, что случайная величина примет значение, меньше заданного 900:
Теперь случайную величину нужно стандартизировать.
Продолжаем вводить обозначения:
z = (X ≤ 900) ;
x = 900 - заданное значение случайной величины;
μ = 1000 - среднее значение;
σ = 200 - стандартное отклонение.
По этим данным условия задачи получаем:
![]() .
.
По таблицам стандартизированной случайной величине (границе интервала) z = −0,5 соответствует вероятность 0,30854. Вычтем ее из единицы и получим то, что требуется в условии задачи:
Итак, вероятность того, что срок службы детали будет не менее 900 часов, составляет 69%.
Эту вероятность можно получить, используя функцию MS Excel НОРМ.РАСП (значение интегральной величины - 1):
P (X ≥900) = 1 - P (X ≤900) = 1 - НОРМ.РАСП(900; 1000; 200; 1) = 1 - 0,3085 = 0,6915.
О расчётах в MS Excel - в одном из последующих параграфах этого урока.
Пример 2. В некотором городе среднегодовой доход семьи является нормально распределённой случайной величиной со средним значением 300000 и стандартным отклонением 50000. Известно, что доходы 40 % семей меньше величины A . Найти величину A .
Решение. В этой задаче 40 % - ни что иное, как вероятность того, что случайная величина примет значение из открытого интервала, меньшее определённого значения, обозначенного буквой A .
Чтобы найти величину A , сначала составим интегральную функцию:
![]()
По условию задачи
μ = 300000 - среднее значение;
σ = 50000 - стандартное отклонение;
x = A - величина, которую нужно найти.
Составляем равенство
![]() .
.
По статистическим таблицам находим, что вероятность 0,40 соответствует значению границы интервала z = −0,25 .
Поэтому составляем равенство
![]()
и находим его решение:
A = 287300 .
Ответ: доходы 40 % семей менее 287300.
Закрытый интервал
Во многих задачах требуется найти вероятность того, что нормально распределённая случайная величина примет значение в интервале от z 1 до z 2 . То есть попадёт в закрытый интервал. Для решения таких задач необходимо найти в таблице вероятности, соответствующие границам интервала, а затем найти разность этих вероятностей. При этом требуется вычитать меньшее значение из большего. Примеры на решения этих распространённых задач - следующие, причём решить их предлагается самостоятельно, а затем можно посмотреть правильные решения и ответы.
Пример 3. Прибыль предприятия за некоторый период - случайная величина, подчинённая нормальному закону распределения со средним значением 0,5 млн. у.е. и стандартным отклонением 0,354. Определить с точностью до двух знаков после запятой вероятность того, что прибыль предприятия составит от 0,4 до 0,6 у.е.
Пример 4. Длина изготавливаемой детали представляет собой случайную величину, распределённую по нормальному закону с параметрами μ =10 и σ =0,071 . Найти с точностью до двух знаков после запятой вероятность брака, если допустимые размеры детали должны быть 10±0,05 .
Подсказка: в этой задаче помимо нахождения вероятности попадания случайной величины в закрытый интервал (вероятность получения небракованной детали) требуется выполнить ещё одно действие.

позволяет определить вероятность того, что стандартизованное значение Z не меньше -z и не больше +z , где z - произвольно выбранное значение стандартизованной случайной величины.
Приближенный метод проверки нормальности распределения
Приближенный метод проверки нормальности распределения значений выборки основан на следующем свойстве нормального распределения: коэффициент асимметрии β 1 и коэффициент эксцесса β 2 равны нулю .
Коэффициент асимметрии β 1 численно характеризует симметрию эмпирического распределения относительно среднего. Если коэффициент асимметрии равен нулю, то среднее арифметрического значение, медиана и мода равны: и кривая плотности распределения симметрична относительно среднего. Если коэффициент асимметрии меньше нуля (β 1 < 0 ), то среднее арифметическое меньше медианы, а медиана, в свою очередь, меньше моды () и кривая сдвинута вправо (по сравнению с нормальным распределением) . Если коэффициент асимметрии больше нуля (β 1 > 0 ), то среднее арифметическое больше медианы, а медиана, в свою очередь, больше моды () и кривая сдвинута влево (по сравнению с нормальным распределением) .
Коэффициент эксцесса β 2 характеризует концентрацию эмпирического распределения вокруг арифметического среднего в направлении оси Oy и степень островершинности кривой плотности распределения. Если коэффициент эксцесса больше нуля, то кривая более вытянута (по сравнению с нормальным распределением) вдоль оси Oy (график более островершинный). Если коэффициент эксцесса меньше нуля, то кривая более сплющена (по сравнению с нормальным распределением) вдоль оси Oy (график более туповершинный).
Коэффициент асимметрии можно вычислить с помощью функции MS Excel СКОС. Если вы проверяете один массив данных, то требуется ввести диапазон данных в одно окошко "Число".

Коэффициент эксцесса можно вычислить с помощью функции MS Excel ЭКСЦЕСС. При проверке одного массива данных также достаточно ввести диапазон данных в одно окошко "Число".

Итак, как мы уже знаем, при нормальном распределении коэффициенты асимметрии и эксцесса равны нулю. Но что, если мы получили коэффициенты асимметрии, равные -0,14, 0,22, 0,43, а коэффициенты эксцесса, равные 0,17, -0,31, 0,55? Вопрос вполне справедливый, так как практически мы имеем дело лишь с приближенными, выборочными значениями асимметрии и эксцесса, которые подвержены некоторому неизбежному, неконтролируемому разбросу. Поэтому нельзя требовать строгого равенства этих коэффициентов нулю, они должны лишь быть достаточно близкими к нулю. Но что значит - достаточно?
Требуется сравнить полученные эмпирические значения с допустимыми значениями. Для этого нужно проверить следующие неравенства (сравнить значения коэффициентов по модулю с критическими значениями - границами области проверки гипотезы).
Для коэффициента асимметрии β 1 .