1 что такое язык sql. SQL программирование. Создание и поддержка простой базы данных
Основные команды SQL, которые должен знать каждый программист
Язык SQL или Structured Query Language (язык структурированных запросов) предназначен для управления данными в системе реляционных баз данных (RDBMS). В этой статье будет рассказано о часто используемых командах SQL, с которыми должен быть знаком каждый программист. Этот материал идеально подойдёт для тех, кто хочет освежить свои знания об SQL перед собеседованием на работу. Для этого разберите приведённые в статье примеры и вспомните, что проходили на парах по базам данных.
Обратите внимание, что в некоторых системах баз данных требуется указывать точку с запятой в конце каждого оператора. Точка с запятой является стандартным указателем на конец каждого оператора в SQL. В примерах используется MySQL, поэтому точка с запятой требуется.
Настройка базы данных для примеров
Создайте базу данных для демонстрации работы команд. Для работы вам понадобится скачать два файла: DLL.sql и InsertStatements.sql . После этого откройте терминал и войдите в консоль MySQL с помощью следующей команды (статья предполагает, что MySQL уже установлен в системе):
Mysql -u root -p
Затем введите пароль.
Выполните следующую команду. Назовём базу данных «university»:
CREATE DATABASE university;
USE university;
SOURCE Может понадобиться создать ограничения для определённых столбцов в таблице. При создании таблицы можно задать следующие ограничения: Можно задать больше одного первичного ключа. В этом случае получится составной первичный ключ. Создайте таблицу «instructor»: CREATE TABLE instructor (ID CHAR(5),
name VARCHAR(20) NOT NULL,
dept_name VARCHAR(20),
salary NUMERIC(8,2),
PRIMARY KEY (ID),
FOREIGN KEY (dept_name) REFERENCES department(dept_name));
Можно просмотреть различные сведения (тип значений, является ключом или нет) о столбцах таблицы следующей командой: DESCRIBE При добавлении данных в каждый столбец таблицы не требуется указывать названия столбцов. INSERT INTO SELECT используется для получения данных из определённой таблицы: SELECT Следующей командой можно вывести все данные из таблицы: SELECT * FROM В столбцах таблицы могут содержаться повторяющиеся данные. Используйте SELECT DISTINCT для получения только неповторяющихся данных. SELECT DISTINCT Можно использовать ключевое слово WHERE в SELECT для указания условий в запросе: SELECT В запросе можно задавать следующие условия: Попробуйте выполнить следующие команды. Обратите внимание на условия, заданные в WHERE: SELECT * FROM course WHERE dept_name=’Comp. Sci.’;
SELECT * FROM course WHERE credits>3;
SELECT * FROM course WHERE dept_name="Comp. Sci." AND credits>3;
Оператор GROUP BY часто используется с агрегатными функциями, такими как COUNT , MAX , MIN , SUM и AVG , для группировки выходных значений. SELECT Выведем количество курсов для каждого факультета: SELECT COUNT(course_id), dept_name
FROM course
GROUP BY dept_name;
Ключевое слово HAVING было добавлено в SQL потому, что WHERE не может быть использовано для работы с агрегатными функциями. SELECT Выведем список факультетов, у которых более одного курса: SELECT COUNT(course_id), dept_name
FROM course
GROUP BY dept_name
HAVING COUNT(course_id)>1;
ORDER BY используется для сортировки результатов запроса по убыванию или возрастанию. ORDER BY отсортирует по возрастанию, если не будет указан способ сортировки ASC или DESC . SELECT Выведем список курсов по возрастанию и убыванию количества кредитов: SELECT * FROM course ORDER BY credits;
SELECT * FROM course ORDER BY credits DESC;
BETWEEN используется для выбора значений данных из определённого промежутка. Могут быть использованы числовые и текстовые значения, а также даты. SELECT Выведем список инструкторов, чья зарплата больше 50 000, но меньше 100 000: SELECT * FROM instructor
WHERE salary BETWEEN 50000 AND 100000;
Оператор LIKE используется в WHERE , чтобы задать шаблон поиска похожего значения. Есть два свободных оператора, которые используются в LIKE: Выведем список курсов, в имени которых содержится «to» , и список курсов, название которых начинается с «CS-»: SELECT * FROM course WHERE title LIKE ‘%to%’;
SELECT * FROM course WHERE course_id LIKE "CS-___";
С помощью IN можно указать несколько значений для оператора WHERE: SELECT Выведем список студентов с направлений Comp. Sci., Physics и Elec. Eng.: SELECT * FROM student
WHERE dept_name IN (‘Comp. Sci.’, ‘Physics’, ‘Elec. Eng.’);
JOIN используется для связи двух или более таблиц с помощью общих атрибутов внутри них. На изображении ниже показаны различные способы объединения в SQL. Обратите внимание на разницу между левым внешним объединением и правым внешним объединением: SELECT Выведем список всех курсов и соответствующую информацию о факультетах: SELECT * FROM course
JOIN department
ON course.dept_name=department.dept_name;
Выведем список всех обязательных курсов и детали о них: SELECT prereq.course_id, title, dept_name, credits, prereq_id
FROM prereq
LEFT OUTER JOIN course
ON prereq.course_id=course.course_id;
Выведем список всех курсов вне зависимости от того, обязательны они или нет: SELECT course.course_id, title, dept_name, credits, prereq_id
FROM prereq
RIGHT OUTER JOIN course
ON prereq.course_id=course.course_id;
View - это виртуальная таблица SQL, созданная в результате выполнения выражения. Она содержит строки и столбцы и очень похожа на обычную SQL-таблицу. View всегда показывает самую свежую информацию из базы данных. Создадим view , состоящую из курсов с 3 кредитами: Эти функции используются для получения совокупного результата, относящегося к рассматриваемым данным. Ниже приведены общеупотребительные агрегированные функции: Вложенные подзапросы - это SQL-запросы, которые включают выражения SELECT , FROM и WHERE , вложенные в другой запрос. Найдём курсы, которые преподавались осенью 2009 и весной 2010 годов: SELECT DISTINCT course_id
FROM section
WHERE semester = ‘Fall’ AND year= 2009 AND course_id IN (SELECT course_id
FROM section
WHERE semester = ‘Spring’ AND year= 2010);
Приветствую вас на моем блоге сайт. Сегодня поговорим про sql запросы для начинающих. У некоторых вебмастеров может возникнуть вопрос. Зачем изучать sql? Разве нельзя обойтись ? Оказывается, что для создания профессионального интернет-проекта этого будет недостаточно. Sql используется чтобы работать с БД и создания приложений для Вордпресс. Рассмотрим, как использовать запросы подробнее. Sql - язык структурированных запросов. Создан для определения типа данных, предоставления доступа к ним и обработке информации за короткие промежутки времени. Он описывает компоненты или какие-то результаты, которые вы хотите видеть на интернет-проекте. Если говорить по-простому, то этот язык программирования позволяет добавлять, изменять, искать и отображать информацию в БД. Популярность mysql связана с тем, что он используется для создания динамических интернет-проектов, основа которых составляет база данных. Поэтому для разработки функционального блога вам необходимо выучить этот язык. Язык sql позволяет: Важно! Разобравшись с sql вы сможете писать приложения для Вордпресс любой сложности. БД состоит из таблиц, которые можно представить в виде Эксель файла. У нее имеется имя, колонки и ряд с какой-то информацией. Создавать подобные таблицы можно при помощи sql запросов. Как уже отмечалось выше, запросы применяются для обработки и ввода новой информации в БД, состоящую из таблиц. Каждая ее строка - это отдельная запись. Итак, создадим БД. Для этого напишите команду: Create database ‘bazaname’
В кавычках пишем имя БД на латинице. Старайтесь придумать для нее понятное имя. Не создавайте базу типа «111», «www» и тому подобное. После создания БД устанавливаем : SET NAMES ‘utf-8’
Это нужно чтобы контент на сайте правильно отображаться. Теперь создаем таблицу: CREATE TABLE ‘bazaname’ . ‘table’ ( id INT(8) NOT NULL AUTO_INCREMENT PRIMARY KEY,
log VARCHAR(10),
pass VARCHAR(10),
date DATE
Во второй строке мы прописали три атрибута. Посмотрим, что они означают: Чтобы заполнить поля созданной таблицы значениями, используется оператор INSERT. Пишем такие строки кода: INSERT INTO ‘table’
(login , pass , date) VALUES
(‘Vasa’, ‘87654321’, ‘2017-06-21 18:38:44’);
В скобках указываем название столбцов, а в следующей - значения. Важно! Соблюдайте последовательность названий и значений столбцов. Для этого используется команда UPDATE. Посмотрим, как изменить пароль для конкретного пользователя. Пишем такие строки кода: UPDATE ‘table’ SET pass = ‘12345678’ WHERE id = ‘1’
Теперь поменяйте пароль ‘12345678’. Изменения происходят в строке с «id»=1. Если не писать команду WHERE - поменяются все строки, а не конкретная. Рекомендую вам приобрести книгу «SQL для чайников
». С ее помощью вы сможете шаг за шагом профессионально работать с БД. Вся информация построена по принципу от простого к сложному, и будет хорошо восприниматься. Если вы написали что-то не так, исправьте это при помощи команды DELETE. Работает так же, как и UPDATE. Пишем такой код: DELETE FROM ‘table’ WHERE id = ‘1’
Для извлечения значений из БД используется команда SELECT. Пишем такой код: SELECT * FROM ‘table’ WHERE id = ‘1’
В данном примере в таблице выбираем все имеющиеся поля. Это происходит если прописать в команде звездочку «*». Если нужно выбрать какое-то выборочное значение пишем так: SELECT log , pass FROM table WHERE id = ‘1’
Необходимо отметить, что умения работать с базами данных будет недостаточно. Для создания профессионального интернет-проекта придется научиться добавлять на страницы данные из БД. Для этого ознакомьтесь с языком веб-программирования php. В этом вам поможет классный курс Михаила Русакова
. Происходит при помощи запроса DROP. Для этого напишем такие строки: DROP TABLE table;
Рассмотрим такой код: SELECT id, countri, city FROM table WHERE people>150000000
Он отобразит записи стран где населения больше ста пятидесяти миллионов. Связать вместе несколько таблиц возможно используя Join. Как это работает посмотрите подробнее в этом видео: Еще раз хочу подчеркнуть, что запросы при создании интернет-проекта - это обычное дело. Чтобы их использовать в php-документах выполните такой алгоритм действий: Важно! Работать с БД не сложно. Главное - правильно написать запрос. Начинающие вебмастера подумают. А что почитать по этой теме? Хотелось бы порекомендовать книгу Мартина Грабера «SQL для простых смертных
». Она написана так, что новичкам все будет понятно. Используйте ее в качестве настольной книги. Но это теория. Как же обстоит дело на практике? В действительности интернет-проект нужно не только создать, но еще и вывести в ТОП Гугла и Яндекса. В этом вас поможет видеокурс «Создание и раскрутка сайта
». Остались еще вопросы? Посмотрите подробнее онлайн видео. Итак, разобраться с написанием sql запросов не так трудно, как кажется, но сделать это нужно любому вебмастеру. В этом помогут видеокурсы, описанные выше. Подпишитесь на мою группу ВКонтакте
чтобы первыми узнавать о появлении новой интересной информации. Для того, чтобы начать изучать SQL
нам нужно сначала понять, что такое база данных. База данных (БД)
- упорядоченный набор логически взаимосвязанных данных, используемых совместно, и которые хранятся в одном месте. Если коротко, то простейшая БД
это обычная таблица со строками и столбцами в которой хранится разного рода информация (примером может служить таблица в Excel
). Так, часто, с БД
нераздельно связывают Системы управления базами данных (СУБД)
, которые предоставляют функционал для работы с БД
. Язык SQL
как раз и является частью СУБД
, которая осуществляет управление информацией в БД
. Мы будем считать БД
набором обычных таблиц, которые хранятся в отдельных файлах. Итак, переходим к SQL
. SQL
- простой язык программирования, который имеет немного команд и которой может научиться любой желающий. Расшифровывается как Structured Query Language
- язык структурированных запросов, который был разработан для работы с БД
, а именно, чтобы получать /добавлять /изменять данные, иметь возможность обрабатывать большие массивы информации и быстро получать структурированную и сгруппированную информацию. Есть много вариантов языка SQL
, но у них всех основные команды почти одинаковы. Также существует и много СУБД
, но основными из них являются: Microsoft Access, Microsoft SQL Server, MySQL, Oracle SQL, IBM DB2 SQL, PostgreSQL та Sybase Adaptive Server SQL
. Чтобы работать с SQL
кодом, нам понадобится одна из вышеперечисленных СУБД
. Для обучения мы будем использовать СУБД Microsoft Access
. SQL
как и другие языки программирования имеет свои команды (операторы), с помощью которых отдаются инструкции для выборки данных.
Чтобы рассмотреть как работают операторы SQL
, мы будем использовать мнимую БД
с информацией о реализованной продукции. Язык программирования
SQL (Structured Query Language — Структурированный язык запросов) — язык управления базами данных для реляционных баз данных. Сам по себе SQL не является Тьюринг-полным языком программирования, но его стандарт позволяет создавать для него процедурные расширения, которые расширяют его функциональность до полноценного языка программирования. Язык был создан в 1970х годах под названием “SEQUEL” для системы управления базами данных (СУБД) System R. Позднее он был переименован в “SQL” во избежание конфликта торговых марок. В 1979 году SQL был впервые опубликован в виде коммерческого продукта Oracle V2. Первый официальный стандарт языка был принят ANSI в 1986 году и ISO — в 1987. С тех пор были созданы еще несколько версий стандарта, некоторые из них повторяли предыдущие с незначительными вариациями, другие принимали новые существенные черты. Несмотря на существование стандартов, большинство распространенных реализаций SQL отличаются так сильно, что код редко может быть перенесен из одной СУБД в другую без внесения существенных изменений. Это объясняется большим объемом и сложностью стандарта, а также нехваткой в нем спецификаций в некоторых важных областях реализации. SQL создавался как простой стандартизированный способ извлечения и управления данными, содержащимися в реляционной базе данных. Позднее он стал сложнее, чем задумывался, и превратился в инструмент разработчика, а не конечного пользователя. В настоящее время SQL (по большей части в реализации Oracle) остается самым популярным из языков управления базами данных, хотя и существует ряд альтернатив. SQL состоит из четырех отдельных частей: Следует отметить, что SQL реализует декларативную парадигму программирования: каждый оператор описывает только необходимое действие, а СУБД принимает решение о том, как его выполнить, т.е. планирует элементарные операции, необходимые для выполнения действия и выполняет их. Тем не менее, для эффективного использования возможностей SQL разработчику необходимо понимать то, как СУБД анализирует каждый оператор и создает его план выполнения. Строка ‘Hello, World!’ выбирается из встроенной таблицы dual , используемой для запросов, не требующих обращения к настоящим таблицам. select
"Hello, World!"
from
dual
;
SQL не поддерживает циклы, рекурсии или пользовательские функции. Данный пример демонстрирует возможный обходной путь, использующий: Строка “0! = 1” не войдет в набор строк, полученный в результате, т.к. попытка вычислить ln(0) приводит к исключению. SQL не поддерживает циклы или рекурсии, кроме того, конкатенация полей из разных строк таблицы или запроса не является стандартной агрегатной функцией. Данный пример использует: SELECT
REPLACE
(MAX
(SYS_CONNECT_BY_PATH
(fib
||
", "
,
"/"
)),
"/"
,
""
)
||
"..."
fiblist
FROM
(
SELECT
n
,
fib
,
ROW_NUMBER
()
OVER
(ORDER
BY
n
)
r
FROM
(select
n
,
round
((power
((1
+
sqrt
(5
))
*
0
.
5
,
n
)
-
power
((1
-
sqrt
(5
))
*
0
.
5
,
n
))
/
sqrt
(5
))
fib
from
(select
level
n
from
dual
connect
by
level
<=
16
)
t1
)
t2
)
START
WITH
r
=
1
CONNECT
BY
PRIOR
r
=
r
-
1
;
select
"Hello, World!"
;
Используется рекурсивное определение факториала, реализованное через рекурсивный запрос. Каждая строка запроса содержит два числовых поля — n и n!, и каждая следующая строка вычисляется с использованием данных из предыдущей. Можно вычислить целочисленные факториалы только до 20!. При попытке вычислить 21! возникает ошибка “Arithmetic overflow error”, т.е. происходит переполнение разрядной сетки. Для вещественных чисел вычисляется факториал 100! (Для этого в примере необходимо заменить bigint на float в 3-ей строке) Используется итеративное определение чисел Фибоначчи, реализованное через рекурсивный запрос. Каждая строка запроса содержит два соседних числа последовательности, и следующая строка вычисляется как (последнее число, сумма чисел) предыдущей строки. Таким образом все числа, кроме первого и последнего, встречаются дважды, поэтому в результат входят только первые числа каждой строки. Этот пример демонстрирует использование оператора model , доступного начиная с версии Oracle 10g и позволяющего обработку строк запроса как элементов массива. Каждая строка содержит два поля — номер строки n и его факториал f. select
n
||
"! = "
||
f
factorial
from
dual
model
return
all
rows
dimension
by
( 0
d
)
measures
( 0
f
,
1
n
)
rules
iterate
(17
)
( f
[
iteration_number
]
=
decode
(iteration_number
,
0
,
1
,
f
[
iteration_number
-
1
]
*
iteration_number
),
n
[
iteration_number
]
=
iteration_number
);
Этот пример демонстрирует использование оператора model , доступного начиная с версии Oracle 10g и позволяющего обработку строк запроса как элементов массива. Каждая строка содержит два поля — само число Фибоначчи и конкатенация всех чисел, меньше или равных ему. Итеративная конкатенация чисел в том же запросе, в котором они генерируются, выполняется проще и быстрее, чем агрегация как отдельное действие. select
max
(s
)
||
", ..."
from
(select
s
from
dual
model
return
all
rows
dimension
by
( 0
d
)
measures
( cast
(" "
as
varchar2
(200
))
s
,
0
f
)
rules
iterate
(16
)
( f
[
iteration_number
]
=
decode
(iteration_number
,
0
,
1
,
1
,
1
,
f
[
iteration_number
-
1
]
+
f
[
iteration_number
-
2
]),
s
[
iteration_number
]
=
decode
(iteration_number
,
0
,
to_char
(f
[
iteration_number
]),
s
[
iteration_number
-
1
]
||
", "
||
to_char
(f
[
iteration_number
]))
)
);
select
concat
(cast
(t2
.
n
as
char
),
"! = "
,
cast
(exp
(sum
(log
(t1
.
n
)))
as
char
))
from
( select
@
i
:
=
@
i
+
1
AS
n
from
TABLE
,
(select
@
i
:
=
0
)
as
sel1
limit
16
)
t1
,
( select
@
j
:
=
@
j
+
1
AS
n
from
TABLE
,
(select
@
j
:
=
0
)
as
sel1
limit
16
)
t2
where
t1
.
n
<=
t2
.
n
group
by
t2
.
n
Замените TABLE на любую таблицу, к которой есть доступ, например, mysql.help_topic . select
concat
(group_concat
(f
separator
", "
),
", ..."
)
from
(select
@
f
:
=
@
i
+
@
j
as
f
,
@
i
:
=
@
j
,
@
j
:
=
@
f
from
TABLE
,
(select
@
i
:
=
1
,
@
j
:
=
0
)
sel1
limit
16
)
t
В этом примере используется анонимный блок PL/SQL, который выводит сообщение в стандартный поток вывода с помощью пакета dbms_output . begin
dbms_output
.
put_line
("Hello, World!"
);
end
;
Этот пример демонстрирует итеративное вычисление факториала средствами PL/SQL. declare
n
number
:
=
0
;
f
number
:
=
1
;
begin
while
(n
<=
16
)
loop
dbms_output
.
put_line
(n
||
"! = "
||
f
);
n
:
=
n
+
1
;
f
:
=
f
*
n
;
end
loop
;
end
;
Этот пример использует итеративное определение чисел Фибоначчи. Уже вычисленные числа хранятся в структуре данных varray — аналоге массива. declare
type
vector
is
varray
(16
)
of
number
;
fib
vector
:
=
vector
();
i
number
;
s
varchar2
(100
);
begin
fib
.
extend
(16
);
fib
(1
)
:
=
1
;
fib
(2
)
:
=
1
;
s
:
=
fib
(1
)
||
", "
||
fib
(2
)
||
", "
;
for
i
in
3
..
16
loop
fib
(i
)
:
=
fib
(i
-
1
)
+
fib
(i
-
2
);
s
:
=
s
||
fib
(i
)
||
", "
;
end
loop
;
dbms_output
.
put_line
(s
||
"..."
);
end
;
Этот пример тестировался в SQL*Plus, TOAD и PL/SQL Developer. Чистый SQL позволяет вводить переменные в процессе исполнения запроса в виде заменяемых переменных. Для определения такой переменной ее имя (в данном случае A, B и C) следует использовать с амперсандом & перед ним каждый раз, когда нужно сослаться на эту переменную. Когда запрос выполняется, пользователь получает запрос на ввод значений всех заменяемых переменных, использованных в запросе. После ввода значений каждая ссылка на такую переменную заменяется на ее значение, и полученный запрос выполняется. Существует несколько способов ввести значения для заменяемых переменных. В данном примере первая ссылка на каждую переменную предваряется не одинарным, а двойным амперсандом && . Таким образом значение для каждой переменной вводится только один раз, а все последующие ссылки на нее будут заменены тем же самым значением (при использовании одиночного амперсанда в SQL*Plus значение для каждой ссылки на одну и ту же переменную приходится вводить отдельно). В PL/SQL Developer ссылки на все переменные должны предваряться одиночным знаком & , иначе будет возникать ошибка ORA-01008 “Not all variables bound”. Первая строка примера задает символ для десятичного разделителя, который используется при преобразовании чисел-корней в строки. Сам запрос состоит из четырех разных запросов. Каждый запрос возвращает строку, содержащую результат вычислений, в одном из случаев (A=0, D=0, D>0 и D<0) и ничего — в трех остальных случаях. Результаты всех четырех запросов объединяются, чтобы получить окончательный результат. alter
session
set
NLS_NUMERIC_CHARACTERS
=
". "
;
select
"Not a quadratic equation."
ans
from
dual
where
&&
A
=
0
union
select
"x = "
||
to_char
(-&&
B
/
2
/&
A
)
from
dual
where
&
A
!=
0
and
&
B
*&
B
-
4
*&
A
*&&
C
=
0
union
select
"x1 = "
||
to_char
((-&
B
+
sqrt
(&
B
*&
B
-
4
*&
A
*&
C
))
/
2
/&
A
)
||
", x2 = "
||
to_char
(-&
B
-
sqrt
(&
B
*&
B
-
4
*&
A
*&
C
))
/
2
/&
A
from
dual
where
&
A
!=
0
and
&
B
*&
B
-
4
*&
A
*&
C
>
0
union
select
"x1 = ("
||
to_char
(-&
B
/
2
/&
A
)
||
","
||
to_char
(sqrt
(-&
B
*&
B
+
4
*&
A
*&
C
)
/
2
/&
A
)
||
"), "
||
"x2 = ("
||
to_char
(-&
B
/
2
/&
A
)
||
","
||
to_char
(-
sqrt
(-&
B
*&
B
+
4
*&
A
*&
C
)
/
2
/&
A
)
||
")"
from
dual
where
&
A
!=
0
and
&
B
*&
B
-
4
*&
A
*&
C
<
0
;
sql часто называют языком эсперанто для систем управления базами данных (СУБД). Действительно, в мире нет другого языка для работы с базами данных (БД), который бы настолько широко использовался в программах. Первый стандарт sol появился в 1986 г. и к настоящему времени завоевал всеобщее признание. Его можно использовать даже при работе с нереляционными СУБД. В отличие от других программных средств, таких, как языки Си и Кобол, являющихся прерогативой программистов-профессионалов, sql применяется специалистами из самых разных областей. Программисты, администраторы СУБД, бизнес-аналитики — все они с успехом обрабатывают данные с помощью sql. Знание этого языка полезно всем, кому приходится иметь дело с БД. В этой статье мы рассмотрим основные понятия sql. Расскажем его предысторию (и развеем попутно несколько мифов). Вы познакомитесь с реляционной моделью и сможете приобрести первые навыки работы с sql, что поможет в дальнейшем освоении языка. Трудно ли изучить sql? Это зависит от того, насколько глубоко вы собираетесь вникать в суть. Для того чтобы стать профессионалом, придется изучить очень многое. Язык sql появился в 1974 г. как предмет небольшой исследовательской работы, состоявшей из 23 страниц, и с тех пор прошел долгий путь развития. Текст действующего ныне стандарта — официального документа "the international standard database language sql" (обычно называемого sql-92) — содержит свыше шести сотен страниц, однако в нем ничего не говорится о конкретных особенностях версий sol, реализованных в СУБД фирм microsoft, oracle, sybase и др. Язык настолько развит и разнообразен, что лишь простое перечисление его возможностей потребует нескольких журнальных статей, а если собрать все, что написано на тему sol, то получится многотомная библиотека. Однако для обычного пользователя совсем не обязательно знать sql целиком и полностью. Как туристу, оказавшемуся в стране, где говорят на непонятном языке, достаточно выучить лишь несколько употребительных выражений и правил грамматики, так и в sql — зная немногое, можно получать множество полезных результатов. В этой статье мы рассмотрим основные команды sql, правила задания критериев для отбора данных и покажем, как получать результаты. В итоге вы сможете самостоятельно создавать таблицы и вводить в них информацию, составлять запросы и работать с отчетами. Эти знания могут стать базой для дальнейшего самостоятельного освоения sql. sql — это специализированный непроцедурный язык, позволяющий описывать данные, осуществлять выборку и обработку информации из реляционных СУБД. Специализированность означает, что sol предназначен лишь для работы с БД; нельзя создать полноценную прикладную систему только средствами этого языка — для этого потребуется использовать другие языки, в которые можно встраивать sql-команды. Поэтому sql еще называют вспомогательным языковым средством для обработки данных. Вспомогательный язык используется только в комплексе с другими языками. В прикладном языке общего назначения обычно имеются средства для создания процедур, а в sql их нет. С его помощью нельзя указать, каким образом должна выполняться некоторая задача, а можно лишь определить, в чем именно она заключается. Другими словами, при работе с sql нас интересуют результаты, а не процедуры для их получения. Наиболее существенным свойством sql является возможность доступа к реляционным БД. Многие даже считают, что выражения "БД, обрабатываемая средствами sql" и "реляционная БД" — синонимы. Однако скоро вы убедитесь, что между ними имеется разница. В стандарте sql-92 даже нет термина отношение (relation). Если не вдаваться в подробности, то реляционная СУБД — это система, основанная на реляционной модели управления данными. Понятие реляционной модели было впервые предложено в работе д-ра Е. Ф. Кодда, опубликованной в 1970 г. В ней был описан математический аппарат для структуризации данных и управления ими, а также предложена абстрактная модель для представления любой реальной информации. До этого при использовании БД требовалось учитывать конкретные особенности хранения в ней информации. Если внутренняя структура БД изменялась (например, с целью повышения быстродействия), приходилось перерабатывать прикладные программы, даже если на логическом уровне никаких изменений не происходило. Реляционная модель позволила отделить частные особенности хранения данных от уровня прикладной программы. В самом деле, модель никак не описывает способы хранения информации и доступа к ней. Учитывается лишь то, как эта информация воспринимается пользователем. Благодаря появлению реляционной модели качественно изменился подход к управлению данными: из искусства оно превратилось в науку, что привело к революционному развитию отрасли. Согласно реляционной модели, отношение (relation) — это некоторая таблица с данными. Отношение может иметь один или несколько атрибутов (признаков), соответствующих столбцам этой таблицы, и некоторое множество (возможно, пустое) данных, представляющих собой наборы этих атрибутов (их называют n-арными кортежами, или записями) и соответствующих строкам таблицы. Для любого кортежа значения атрибутов должны принадлежать так называемым доменам. Фактически доменом является некоторый набор данных, который задает множество всех допустимых значений. Давайте рассмотрим пример. Пусть имеется домен ДниНедели, содержащий значения от Понедельник до Воскресенье. Если отношение имеет атрибут ДеньНедели, соответствующий этому домену, то в любом кортеже отношения в столбце ДеньНедели должно присутствовать одно из перечисленных значений. Появление значений Январь или Кошка не допускается. Обратите внимание: атрибут обязательно должен иметь одно из допустимых значений. Задание сразу нескольких значений запрещено. Таким образом, помимо требования принадлежности значений атрибута некоторому домену, должно соблюдаться условие его атомарности. Это означает, что для этих значений недопустима декомпозиция, т. е. нельзя разбить их на более мелкие части, не потеряв основного смысла. Например, если бы значение атрибута одновременно содержало Понедельник и Вторник, то можно было бы выделить две части, сохранив первоначальный смысл — ДеньНедели; следовательно, это значение атрибута не является атомарным. Однако если попробовать разбить значение "Понедельник" на части, то получится набор из отдельных букв — от "П" до "К"; исходный смысл утерян, поэтому значение "Понедельник" является атомарным. Отношения обладают и другими свойствами. Наиболее значимое из них — математическое свойство замкнутости операций. Это означает, что в результате выполнения любой операции над отношением должно появляться новое отношение. Это свойство позволяет при выполнении математических операций над отношениями получать предсказуемые результаты. Кроме того, появляется возможность представлять операции в виде абстрактных выражений с разными уровнями вложенности. В своей исходной работе д-р Кодд определил набор из восьми операторов, получивший название реляционной алгебры. Четыре оператора — объединение, логическое умножение, разность и Декартово произведение — были перенесены из традиционной теории множеств; остальные операторы были созданы специально для обработки отношений. В последующих работах д-ра Кодда, Криса Дейта и других исследователей были предложены дополнительные операторы. Далее в этой статье будут рассмотрены три реляционных оператора — продукция (project), ограничения (select, или restrict) и слияние (join). Теперь, когда вы познакомились с реляционной моделью, давайте забудем о ней. Конечно, не навсегда, а лишь для того, чтобы объяснить следующее: хотя именно предложенная д-ром Коддом реляционная модель была использована при разработке sql, между ними нет полного или буквального соответствия (это одна из причин, почему в стандарте sql-92 отсутствует термин отношение). Например, понятия таблица sql и отношение не являются равнозначными, потому что в таблицах может быть сразу несколько одинаковых строк, тогда как в отношениях появление идентичных кортежей не разрешено. К тому же в sql не предусмотрено использование реляционных доменов, хотя в некоторой степени их роль играют типы данных (некоторые влиятельные сторонники реляционной модели предпринимают сейчас попытку добиться включения в будущий стандарт sql реляционных доменов). К сожалению, несоответствие между sql и реляционной моделью породило множество недоразумений и споров за прошедшие годы. Но так как основная тема статьи — изучение sql, а не реляционной модели, эти проблемы здесь не рассматриваются. Просто следует запомнить, что между терминами, применяемыми в sql и в реляционной модели, имеются различия. Далее в статье будут использоваться только термины, принятые в sql. Вместо отношений, атрибутов и кортежей будем применять их sql-аналоги: таблицы, столбцы и строки. Возможно, вам уже знакомы такие термины, как статический и динамический sql. sql-запрос является статическим, если он компилируется и оптимизируется на стадии, предшествующей выполнению программы. Мы уже упоминали одну из форм статического sql, когда говорили о встраивании sql-команд в программы на Си или Коболе (для таких выражений существует еще другое название — встроенный sql). Как вы, наверное, догадываетесь, динамический sql-запрос компилируется и оптимизируется в ходе исполнения программы. Как правило, обычные пользователи применяют именно динамический sql, позволяющий создавать запросы в соответствии с сиюминутными нуждами. Один из вариантов изпользования динамических sql-запросов — их интерактивный или непосредственный вызов (существует даже специальный термин — directsql), когда отправляемые на обработку запросы вводятся в интерактивном режиме с терминала. Между статическим и динамическим sql имеются определенные различия в синтаксисе применяемых конструкций и особенностях исполнения, однако эти вопросы выходят за рамки статьи. Отметим лишь, что для ясности понимания примеры даются в форме direct sql-запросов, поскольку это позволяет научиться использовать sql не только программистам, но и большинству конечных пользователей. Теперь вы готовы к написанию своих первых sql-запросов. Если у вас имеется доступ к БД через sql и вы захотите воспользоваться нашими примерами на практике, то учтите следующее: вы должны входить в систему как пользователь с неограниченными полномочиями и вам потребуются программные средства интерактивной обработки sql-запросов (если речь идет о сетевой БД, следует переговорить с администратором БД о предоставлении вам соответствующих прав). Если доступа к БД через sql нет — не огорчайтесь: все примеры очень простые и в них можно разобраться "всухую", без выхода на машину. Для того чтобы выполнить какие-либо действия в sql, следует выполнить выражение на языке sql. Встречается несколько типов выражений, однако среди них можно выделить три основные группы: ddl-команды (data definition language — язык описания данных), dml-команды (data manipulation language — язык манипуляций с данными) и средства контроля за данными. Таким образом, в sql в каком-то смысле объединены три различных языка. Начнем с одной из основных ddl-команд — create table (Создать таблицу). В sql бывают таблицы нескольких типов, основными являются два типа: базовые (base) и выборочные (views). Базовыми являются таблицы, относящиеся к реально существующим данным; выборочные — это "виртуальные" таблицы, которые создаются на основе информации, получаемой из базовых таблиц; но для пользователей формы выглядят как обычные таблицы. Команда create table предназначена для создания базовых таблиц. В команде create table следует задать название таблицы, указать список столбцов и типы содержащихся в них данных. В качестве параметров могут присутствовать также другие необязательные элементы, однако сначала давайте рассмотрим только основные параметры. Покажем простейшую синтаксическую форму для этой команды: create table ИмяТаблицы (Столбец ТипДанных) ; create и table — это ключевые слова sql; ИмяТаблицы, Столбец и ТипДанных — это формальные параметры, вместо которых пользователь каждый раз вводит фактические значения. Параметры Столбец и ТипДанных заключены в круглые скобки. В sql круглые скобки обычно используются для группировки отдельных элементов. В данном случае они позволяют объединить определения для столбца. Стоящий в конце знак "точка с запятой" является разделителем команд. Он должен завершать любое выражение на языке sql. Рассмотрим пример. Пусть нужно создать таблицу для хранения данных обо всех встречах (appointments). Для этого в sql следует ввести команду: create table appointments (appointment_date date) ; После выполнения этой команды будет создана таблица с именем appointments, где имеется один столбец appointment_date, в котором могут записываться данные типа date. Поскольку на текущий момент данные еще не вводились, количество строк в таблице равно нулю (с помощью команды create table только дается определение таблицы; реальные значения вводятся командой insert, которая рассматривается далее). Параметры appointments и appointment_date называются идентификаторами, поскольку они задают имена для конкретных объектов БД, в данном случае — имена для таблицы и столбца соответственно. В sql встречаются идентификаторы двух типов: обычные (regular) и выделенные (delimited). Выделенные идентификаторы заключаются в двойные кавычки, и в них учитывается регистр используемых символов. Обычные идентификаторы не выделяются никакими ограниченными символами, в их написании регистр не учитывается. В этой статье применяются только обычные идентификаторы. Символы, используемые для построения идентификаторов, должны удовлетворять определенным правилам. В обычных идентификаторах могут использоваться только буквы (не обязательно латинские, но и других алфавитов), цифры и символ подчеркивания. Идентификатор не должен содержать знаков пунктуации, пробелов или специальных символов (#, @, % или!); кроме того, он не может начинаться с цифры или знака подчеркивания. Для идентификаторов можно использовать отдельные ключевые слова sql, но делать это не рекомендуется. Идентификатор предназначен для обозначения некоторого объекта, поэтому у него должно быть уникальное (в рамках определенного контекста) имя: нельзя создать таблицу с именем, которое уже встречается в БД; в одной таблице нельзя иметь столбцы с одинаковыми именами. Кстати, имейте в виду, что appointments и appointments — это одинаковые имена для sql. Одним лишь изменением регистра букв создать новый идентификатор нельзя. Хотя таблица может иметь всего один столбец, на практике обычно требуются таблицы с несколькими столбцами. Команда для создания такой таблицы в общем виде выглядит так: create table ИмяТаблицы (Столбец ТипДанных [ { , Столбец ТипДанных } ]) ; Квадратные скобки использованы для обозначения необязательных элементов, фигурные содержат элементы, которые могут представлять собой перечень однопутных конструкций (при вводе реальной sql-команды ни те ни другие скобки не ставятся). Такой синтаксис позволяет задать любое число столбцов. Обратите внимание, что перед вторым элементом стоит запятая. Если в списке имеется несколько параметров, то они отделяются друг от друга запятыми. create table appointments2 (appointment_date date ,
appointment_time time ,
description varchar (256)) ; Данная команда создает таблицу appointments2 (новая таблица должна иметь иное имя, так как таблица appointments уже присутствует в БД). Как и в первой таблице, в ней имеется столбец appointment_date для записи даты встреч; кроме того, появился столбец appointment_time для записи времени этих встреч. Параметр description (описание) является текстовой строкой, где может содержаться до 256 символов. Для этого параметра указан тип varchar (сокращение от character varying), поскольку заранее не известно, сколько места потребуется для записи, но ясно, что описание займет не более 256 символов. При описании параметро в типа символьная строка (и некоторых других типов) указывается длина параметра. Ее значение задается в круглых скобках справа от названия типа. Возможно, вы обратили внимание, что в двух рассмотренных примерах запись команды оформлена по-разному. Если в первом случае команда полностью размещена в одной строке, то во втором после первой открытой круглой скобки запись продолжена с новой строки, и определение каждого следующего столбца начинается с новой строки. В sql нет специальных требований к оформлению записи. Разбиение записи на строки делает ее чтение удобнее. Язык sql позволяет при написании команд не только разбивать команду по строкам, но и вставлять отступы в начале строк и пробелы между элементами записи. Теперь, когда вы знаете основные правила, давайте рассмотрим более сложный пример создания таблицы с несколькими столбцами. В начале статьи была показана таблица employees (Сотрудники). В ней содержатся следующие столбцы: фамилия, имя, дата приема на работу, подразделение, категория и зарплата за год. Для определения этой таблицы используется следующая команда sql: create table employees (last_name character (13) not null,
first_name character (10) not null,
hire_date date ,
branch_office character (15) ,
grade_level smallint ,
salary decimal (9 , 2)) ; В команде встречаются несколько новых элементов. Прежде всего, это выражение not null, стоящее в конце определения столбцов last_name и first_name. С помощью подобных конструкций задаются требования, подлежащие обязательному соблюдению. В данном случае указано, что поля last_name и first_name должны обязательно заполняться при вводе; оставлять эти столбцы пустыми нельзя (это вполне логично: как можно идентифицировать сотрудника, не зная его имени?). Кроме того, в примере присутствуют три новых типа данных: character, smallint и decimal. До сих пор мы почти не говорили о типах. Хотя в sql нет реляционных доменов, однако имеется набор основных типов данных. Эта информация используется при выделении памяти и сравнении величин; в определенной степени сужает список возможных значений при вводе, однако контроль типов в sql менее строгий, чем в других языках. Все имеющиеся в sql типы данных можно разбить на шесть групп: символьные строки, точные числовые значения, приближенные числовые значения, битовые строки, датовремя и интервалы. Мы перечислили все разновидности, однако в этой статье подробно будут рассматриваться лишь отдельные из них (битовые строки, например, не представляют особого интереса для обычных пользователей). Кстати, если вы подумали, что датовремя — это опечатка, то ошиблись. К данной группе (datetime) относится большинство используемых в sql типов данных, связанных со временем (такие параметры, как временные интервалы, выделены в отдельную группу). В предыдущем примере уже встречались два типа данных из группы датовремя — date и time. Следующий тип данных, с которым вы уже знакомы, — character varying (или просто varchar); он относится к группе символьных строк. Если varchar служит для хранения строк переменной длины, то встретившийся в третьем примере тип char предназначен для записи строк, имеющих фиксированное число символов. Например, в столбце last_name будут записываться строки из 13 символов вне зависимости от реально вводимых фамилий, будь то poe или penworth-chickering (в случае с poe оставшиеся 10 символов заполнятся пробелами). С точки зрения пользователя, varchar и char имеют одинаковый смысл. Зачем нужно было вводить два типа? Дело в том, что на практике обычно приходится искать компромисс между быстродействием и экономией пространства на диске. Как правило, применение строк с фиксированной длиной дает некоторый выигрыш в скорости доступа, однако при слишком большой длине строк пространство на диске расходуется неэкономно. Если в appointments2 для каждой строки комментария резервировать по 256 символов, то это может оказаться нерационально; чаще всего строки будут значительно короче. С другой стороны, фамилии также имеют разную длину, но для них, как правило, требуется около 13 символов; в этом случае потери будут минимальными. Существует хорошее правило: если известно, что длина строки меняется незначительно либо она сравнительно невелика, то используйте char; в остальных случаях — varchar. Следующие два новых типа данных — smallint и decimal — относятся к группе точных числовых значений. smallint — это сокращенное название от small integer (малое целое). В sql также предусмотрен тип данных integer. Наличие двух схожих типов и в этом случае объясняется соображением экономии пространства. В нашем примере значения параметра grade_level могут быть представлены с помощью двузначного числа, поэтому использован тип smallint; однако на практике не всегда известно, какие максимальные значения могут быть у параметров. Если такой информации нет, то применяйте integer. Реальный объем, выделяемый для хранения параметров типа smallint и integer, и соответствующий диапазон значений для этих параметров индивидуальны для каждой платформы. Тип данных decimal, обычно используемый для учета финансовых показателей, позволяет задать шаблон с требуемым числом десятичных знаков. Поскольку этот тип служит для точной числовой записи, он гарантирует точность при выполнении математических операций над десятичными данными. Если для десятичных значений использовать типы данных из группы приближенной числовой записи, например float (floating point number — число с плавающей точкой), это приведет к погрешностям округления, поэтому для финансовых расчетов этот вариант не подходит. Для определения параметров типа decimal используется следующая форма записи: где p — это число десятичных знаков, d — количество разрядов после запятой. Вместо p следует записывать общее число значащих цифр в используемых значениях, а вместо d — количество цифр после запятой. Во врезке "Создание таблицы" показан полный вариант обобщенной записи команды create table. В нем присутствуют новые элементы и показан формат для всех рассмотренных типов данных (В принципе встречаются и другие типы данных, но пока мы их не рассматриваем). На первых порах может показаться, что синтаксис sql-команд слишком сложен. Но вы легко в нем разберетесь, если внимательно изучили приведенные выше примеры. На схеме появился дополнительный элемент — вертикальная черта; он служит для разграничения альтернативных конструкций. Другими словами, при определении каждого столбца нужно выбрать подходящий тип данных (как вы помните, в квадратные скобки заключаются необязательные параметры, а в фигурные скобки — конструкции, которые могут повторяться многократно; в реальных sql-командах эти специальные символы не пишутся). В первой части схемы приведены полные названия для типов данных, во второй — их сокращенные названия; на практике можно использовать любые из них. Первая часть статьи завершена. Вторая будет посвящена изучению dml-команд insert, select, update и delete. Также будут рассмотрены условия выборки данных, операторы сравнения и логические операторы, использование null-значений и троичная логика. Создание таблицы. Синтаксис команды create table: в квадратных скобках указаны необязательные параметры, в фигурных — повторяющиеся конструкции. create table table (column character (length) [ constraint ] |
character varying (length) [ constraint ] |
date [ constraint ] |
time [ constraint ] |
integer [ constraint ] |
smallint [ constraint ] |
decimal (precision, decimal places) [ constraint ] |
float (precision) [ constraint ]
[{ , column char (length) [ constraint ] |
varchar (length) [ constraint ] |
date [ constraint ] |
time [ constraint ] |
int [ constraint ] |
smallint [ constraint ] |
dec (precision, decimal places) [ constraint ] |
float (precision) [ constraint ] }]) ; В начале 1970-х гг. в ibm приступили к практическому воплощению модели реляционных БД, предложенной д-ром Коддом. Дональд Чамберлин и группа других сотрудников подразделения перспективных исследований создали прототип языка, получивший название structured english query language (язык структурированных англоязычных запросов), или просто sequel. В дальнейшем он был расширен и подвергнут доработке. Новый вариант, предложенный ibm, получил название sequel/2. Его использовали как программный интерфейс (api) для проектирования первой реляционной системы БД фирмы ibm — system/r. Из соображений, связанных с правовыми нюансами, в ibm решили изменить название: вместо sequel/2 использовать sql (structured query language). Эту аббревиатуру часто произносят как "си-ку-эл".Команды для работы с базами данных
1. Просмотр доступных баз данных
SHOW DATABASES;
2. Создание новой базы данных
CREATE DATABASE;
3. Выбор базы данных для использования
USE 4. Импорт SQL-команд из файла.sql
SOURCE 5. Удаление базы данных
DROP DATABASE Работа с таблицами
6. Просмотр таблиц, доступных в базе данных
SHOW TABLES;

7. Создание новой таблицы
CREATE TABLE Ограничения целостности при использовании CREATE TABLE
Пример
8. Сведения о таблице

9. Добавление данных в таблицу
INSERT INTO 10. Обновление данных таблицы
UPDATE 11. Удаление всех данных из таблицы
DELETE FROM 12. Удаление таблицы
DROP TABLE Команды для создания запросов
13. SELECT

14. SELECT DISTINCT

15. WHERE
Пример

16. GROUP BY
Пример

17. HAVING
Пример

18. ORDER BY
Пример

19. BETWEEN
Пример

20. LIKE
SELECT Пример

21. IN
Пример

22. JOIN

Пример 1

Пример 2

Пример 3

23. View
Создание
CREATE VIEW Удаление
DROP VIEW Пример

24. Агрегатные функции
25. Вложенные подзапросы
Пример

Что это такое
Что может делать
Какая структура
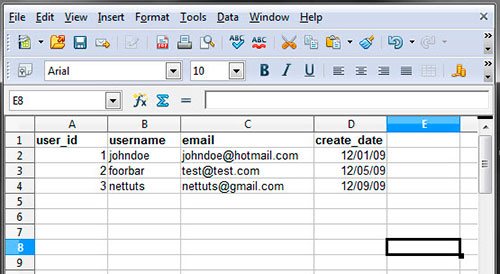
Что нужно знать

Основные моменты при изучении Sql

Как добавить информацию
Как обновить информацию

Как удалить запись
Выборка информации

Удаление таблицы
Вывод записи из таблицы по определенному условию
Объединение
PHP и MySQL


Видео инструкция
Вывод
1. Что такое База Данных
2. Что такое SQL
Примеры:
Hello, World!:
Пример для версий
Oracle 10g SQL ,
Oracle 11g SQL
Факториал:
Пример для версий
Oracle 10g SQL ,
Oracle 11g SQL
Числа Фибоначчи:
Пример для версий
Oracle 10g SQL ,
Oracle 11g SQL
Hello, World!:
Пример для версий
Microsoft SQL Server 2005 ,
Microsoft SQL Server 2008 R2 ,
Microsoft SQL Server 2012 ,
MySQL 5 ,
PostgreSQL 8.4 ,
PostgreSQL 9.1 ,
sqlite 3.7.3
Факториал:
Пример для версий
Microsoft SQL Server 2005 ,
Microsoft SQL Server 2008 R2 ,
Microsoft SQL Server 2012
Числа Фибоначчи:
Пример для версий
Microsoft SQL Server 2005 ,
Microsoft SQL Server 2008 R2 ,
Microsoft SQL Server 2012
Факториал:
Пример для версий
Oracle 10g SQL ,
Oracle 11g SQL
Числа Фибоначчи:
Пример для версий
Oracle 10g SQL ,
Oracle 11g SQL
Факториал:
Пример для версий
MySQL 5
Числа Фибоначчи:
Пример для версий
MySQL 5
Hello, World!:
Пример для версий
Oracle 10g SQL ,
Oracle 11g SQL
Факториал:
Пример для версий
Oracle 10g SQL ,
Oracle 11g SQL
Числа Фибоначчи:
Пример для версий
Oracle 10g SQL ,
Oracle 11g SQL
Квадратное уравнение:
Пример для версий
Oracle 10g SQL ,
Oracle 11g SQL
Что такое sql?
Что такое реляционная СУБД?
Основные понятия реляционной модели
sql и реляционная модель
Статический и динамический sql
Как изучать sql
Команды языка описания данных
Секрет названия sql